BDNA Data Platform 5.5
Unmatched files refer to zip package files that are generated by a Normalize process and stored locally (where Normalize is installed). The name of the zip package file uses the following naming convention:
Unmatched_[Company_Identifier]_timestamp_[task_id]
For example: Unmatched_ACMECompany_1704222148_16752.zip
Note • With the latest release of Normalize, the Company Identifier now uses the Org GUID (HASH) characters (as opposed to plain text).
This Unmatched zip package file contains multiple csv files:
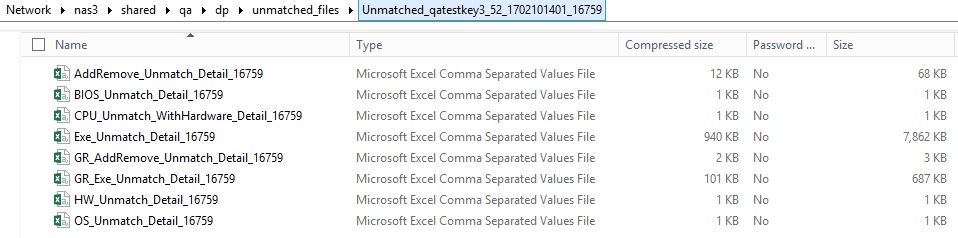
| • | AddRemove_Unmatch_Detail_[task_id] |
| • | BIOS_Unmatch_Detail_[task_id] |
| • | CPU_Unmatch_WithHardware_Detail_[task_id] |
| • | Exe_Unmatch_Detail_[task_id] |
| • | GR_AddRemove_Unmatch_Detail_[task_id] |
| • | GR_Exe_Unmatch_Detail_[task_id] |
| • | HW_Unmatch_Detail_[task_id] |
| • | OS_Unmatch_Detail_[task_id] |
The first argument in those file names indicate which table in the Normalize schema the data comes from (i. e. from AddRemove table, BIOS table, Exe table, and so on). Note that there are some files that are prefixed with a GR_ string to indicate that the file contains usage metering data (if it's enabled in the discovery tool). Every file contains the 'Unmatch_Detail' argument, and is suffixed by the task ID.
Each of the Unmatch_Detail files contain the 'unmatched' entries (i.e. entries that contain no matching string in the existing BDNA Normalize mapping signatures). For example, the AddRemove_Unmatch file contains entries from the AddRemove table in Normalize that returns no match with any mapping signature. This happens in this instance because Normalize has never seen any data that matches this exact string in the past. As a consequence, these entries will return neither Technopedia data nor the indication that it is 'Irrelevant' in Normalize reports. Customers generally would like to see the entries to be either 'Mapped' or marked as 'Irrelevant', therefore they may choose to (optionally) have them go through the 'gap-fill' process.
Sample of an Unmatched File:
BDNA Data Platform 5.5 Administration Help Library02 August 2016 |
Copyright Information | Flexera |